Is Vibe Coding Safe? A Tale of Two Research Studies.

Date
Authors
Tony UV
Follow Us
Firstly, excellent research and analysis, such as the one put out by Carnegie Mellon University’s Language Technologies Institute will continue to be both vital to follow since models are constantly changing in both the algos developed by AI providers like OpenAI, Anthropic, Google, etc. and the data sources that are used to train these models. This type of research stands as a fundamental question that we all will need to be asking weekly if not more often within companies that are allowing their employees to engage in vibe coding as a means to quickly solve simple problems or (in a worse case) in support of pull requests on product solutions that are supporting business operations and real data. As most real developers use AI assisted plugins within their development efforts to catalyze faster completion of feature requests in backlogs, vibe coding is used by non-developers or novice developers and therefore introducing both functional and security concerns that are both real and notable. Separate to this university based research and also of noteworthy importance and praise is the great research from a researcher at Invicti – for an impressive sample size of vibe coded apps that were put through the gauntlet of security tests commonly performed within enterprise #AppSec programs.
Just to level set on the definition, #VibeCoding is a programming paradigm where developers give natural language instructions to AI language models (like ChatGPT, Claude, or Cursor) to complete complex coding tasks with little to no supervision or detailed oversight. Personally, my thoughts are that vibe coding has a place and like anything new can be either properly leveraged to catalyze development work or improperly used to produce slop code that is a liability to a product team. There is no question that AI is proving to be an invaluable partner to the experienced professional who can qualify output from AI assisted development plugins. But AI assisted coding and vibe coding are two distinct things. Experienced software developers already have some knowledge of what to automate or where to leverage AI given their years of expertise across multiple different language sets and frameworks. Vibe coders do not have this expertise and therein lies a huge problem wherein inexperienced team members get a false sense they know how to build software because of the ease of vibe coding ideas into software products. The danger clearly is in unleashing a power to someone that has never formally written an organic line of code before. This comparative analysis made in this article therefore is NOT speaking on the merits of AI assisted plugins aiding real developers, but rather the pandora’s box of vibe coding practices in a community of non-developers.
This article really examines two distinct studies that were very recent. One done as part of a university collab and the other more from private firm. Both studies have reputable formats in their studies and produce interesting results. For me (and hopefully for you) we have to recognize that these studies will be required to be examined more often as an industry and even as part of internal benchmarking research within companies and groups that are looking to analyze the fruits (or spoils) of vibe coding efforts. It’s important to remind that at this stage of where we are with AI inclusion in software development and product build outs, that there shouldn’t be a conclusive study that encourages or disuades those that are considering vibe coding. As with anything new, there are truly valuable assets to vibe coding however these studies do manifest a dichotomy from their research on clear gaps in accuracy and reliability but at the same time opportunities to truly operationalize security at scale by extrapolating and operationalizing the functional parts that do work and to ensure continued benchmarking as part of the process.
Let’s begin.

SusVibes Vibe Coding & Security Study #1
SusVibes Main Finding: AI-Generated Code is Functionally Correct but Dangerously Insecure
The SusVibes benchmark includes 200 coding tasks that cover 77 different types of security weaknesses (from the Common Weakness Enumeration database). Unlike synthetic test cases, these tasks come from vulnerabilities that actually fooled human developers in production code, making them highly realistic measures of AI security capabilities. This aspect is super important to consider when you read through their actual research. In essence, the a benchmark of 200 real-world coding tasks that historically led human programmers to create vulnerable code. Testing leading AI coding agents revealed alarming results:
- Claude 4 Sonnet achieved 61% functional correctness, but only 10.5% of solutions were secure
- Over 80% of functionally correct code contained security vulnerabilities
- Simple security prompts failed to fix the problem and actually degraded functional correctness by about 6%
Notable Takeaways in the SusVibes Benchmark Analysis:
- The Security Gap is Massive: All tested agents performed poorly on security despite strong functional performance. Even when code appears to work correctly, it often contains exploitable vulnerabilities.
- Common Vulnerabilities: The most frequent security issues included code injection, command injection, integer overflow, missing authentication, and unrestricted file uploads – all from the industry-standard CWE (Common Weakness Enumeration) list.
- Real-World Impact: Examples included timing attacks that enable username enumeration, header injection vulnerabilities allowing session hijacking, and missing session expiration checks that defeat authentication timeouts.
- Mitigation Attempts Failed: Researchers tried providing security hints, having AI identify risks first, and even giving the exact vulnerability type to avoid. None worked well – they reduced functional correctness without significantly improving security.
- Different AI Models Have Different Blind Spots: 58% of vulnerability types were not overlapped among the three tested models, meaning each AI is good at avoiding different security issues.
Bottom line: AI coding assistants are great productivity tools but currently cannot be trusted to write secure code without expert human review, particularly for security-sensitive applications.
Invicti Vibe Coding & Security Study #2
What’s really interesting about this study is that separately a month ago, a security researcher vibe coded 20,000+ apps and tested the security posture of those apps to see how they faired and found the OPPOSITE results as compared to the below SusVibes analysis done. In that prior research, the research vibe code 20,000+ apps and then benchmarked their security and found interesting results on the security vulnerabilities that were produced. The Invicti research was also a well put together research with a great transparency on the models used, the sample size and the types of security tests conducted.
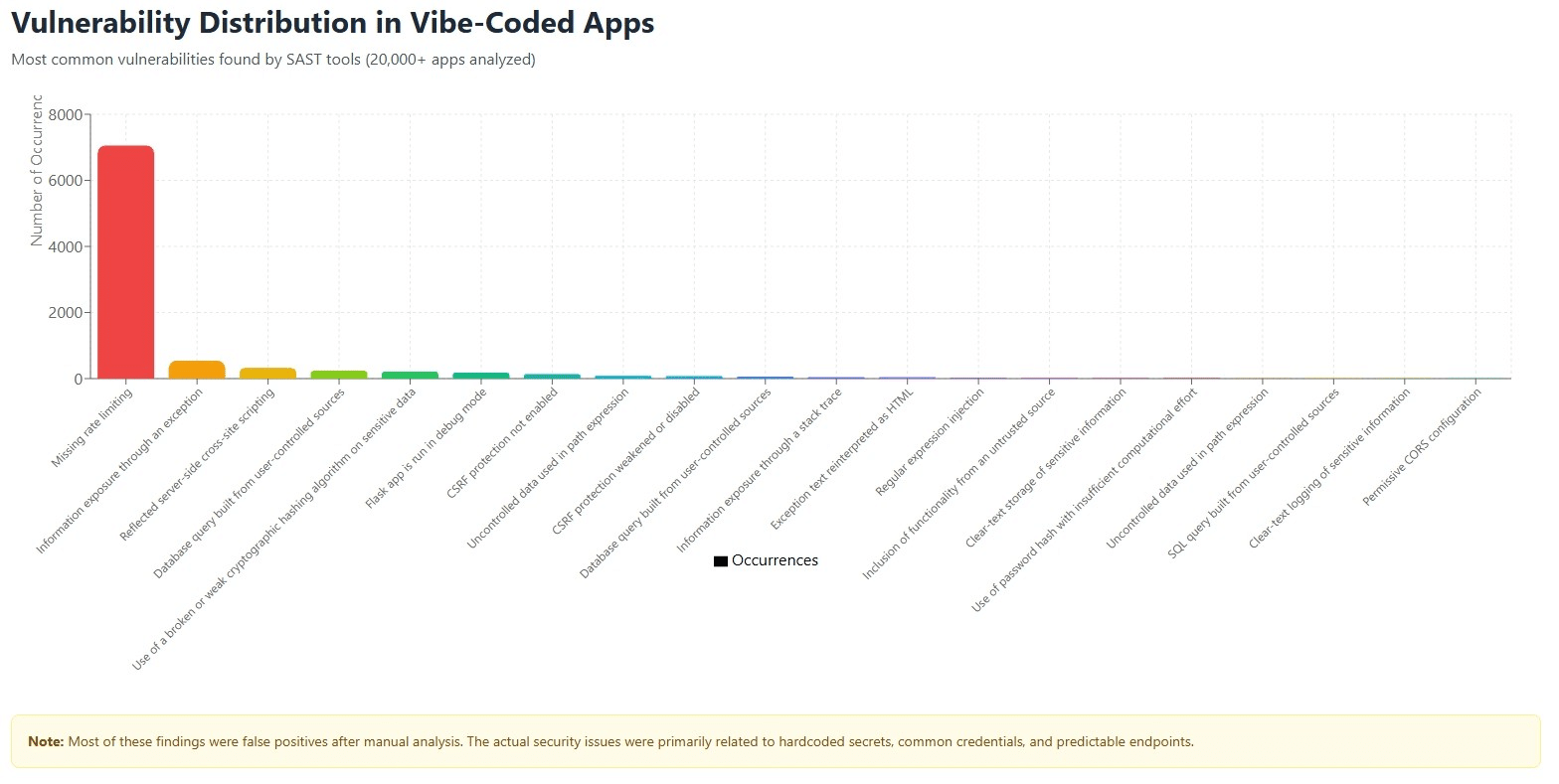
Occurrences & Types of Security Weaknesses Across Sample Size of Vulnerable Apps
Main Findings from the Invicti Study Reveals Greater Inclusion of Security in Vibe Coded Apps
1. Dramatic Security Improvement for Traditional Vulnerabilities: Modern LLMs are “much better from a security point of view” than early AI coding assistants, with far fewer cases of SQL injection, XSS, path traversal, and other common vulnerabilities
2. LLMs Reuse Predictable Secrets: Each LLM model has its own set of common secrets that it reuses repeatedly across different generated apps
- “supersecretkey” appeared in 1,182 out of 20,000 apps
- “supersecretjwt” was the most common JWT secret
3. Hardcoded Secrets Are Everywhere: Many vibe-coded apps use hardcoded secrets for JWT signatures, API keys, database passwords, and other sensitive information
4. Common Credentials Problem: Apps often use hardcoded common credentials like “[email protected]:password123″ and “[email protected]:password”
5. Predictable Endpoints: Common login/registration endpoints like /api/login, /api/register, /auth/login make apps easy to target
6. Easy Exploitation: Using predictable secrets, attackers can forge JWT tokens and gain admin privileges by simply decoding, modifying, and re-signing tokens
7. Root Cause is Fundamental: Security flaws are caused by hardcoded secrets replicated from LLM training data, and “it’s hard to prevent such behaviors because they are built into models”
8. SAST Tools Largely Ineffective: Most issues reported by static analysis tools were false positives, with only a handful being real vulnerabilities after manual analysis
9. Scale of Research: The research conducted provided a healthy sample size of vibe coded apps that encompassed the following attributes in the study:
- 20,656 web applications generated
- Multiple LLMs tested (GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro, DeepSeek, Qwen)
- Various technologies and frameworks
- Dataset made publicly available on Hugging Face
10. Industry Adaptation Required: Invicti created new DAST security checks specifically for vibe-coded vulnerabilities, including testing JWT tokens against common secrets and trying common credentials on predictable endpoint
Notable Takeaways from Invicti Study:
The Good News: Modern LLMs are WAY better at avoiding basic vulnerabilities like SQL injection and XSS compared to 3 years ago
The Bad News: 2. 1,182 apps (out of 20,000) used the exact same secret: “supersecretkey”
- Each AI model has “favorite” hardcoded secrets it reuses across different apps
- Common credentials like “[email protected]:password” appear everywhere
- Attackers can forge admin JWT tokens in seconds using predictable secrets
- These flaws are “built into models” from training data – you can’t prompt your way out
- Most SAST tool findings were false positives – traditional security scanning doesn’t work well
Bottom Line: AI has gotten better at writing secure code, but it systematically copies insecure configurations from its training data. This creates predictable patterns attackers can exploit at scale.
So which one is it? Is Vibe Coding Good or Bad?
These two studies reach surprisingly different conclusions about vibe coding security, and the differences reveal important nuances that are both important to consider. The research done is great, there are key variations to their respective research parameters, but both provide great insights in the ongoing need to understand the both the opportunities and risks related to vibe coding. Let’s dissect the surface level differences and see the commonalities across the two pieces of research.
1. In Assessing Security, there is Major Disagreement
SusVibes (Pessimistic):
- Only 10.5% of Claude 4 Sonnet’s solutions were secure, despite 61% being functionally correct
- Over 80% of working code contained exploitable vulnerabilities
- Conclusion: AI code is dangerously insecure
2. Research Variances in Vulns Found – Key Differences
SusVibes focused on:
- Traditional code-level vulnerabilities (SQL injection, XSS, CRLF injection)
- Logic flaws (timing attacks, session handling)
- Missing security checks in complex workflows
- Repository-level security issues requiring understanding of entire codebases
Invicti focused on:
- Hardcoded secrets (JWT secrets, API keys, database passwords) replicated from LLM training data
- Common credentials like “[email protected]:password123” reused across apps
- Predictable endpoints
- Configuration issues
3. Methodology Differences Explain the Gap
SusVibes:
- 200 repository-level tasks based on real-world vulnerabilities that fooled human developers
- Complex, multi-file editing scenarios
- Tasks specifically designed to expose security weaknesses
- Tested AI agents in realistic development workflows
Invicti:
- Generated 20,000 complete web applications from scratch with prompts asking for “production-ready” apps
- Manual analysis found most SAST tool findings were false positives
- Focused on common patterns across many simple apps
- Did not test complex integration scenarios
4. Quality of Vulnerabilities
SusVibes vulnerabilities:
- Subtle logic flaws requiring deep code understanding
- Example: Timing side-channels that enable username enumeration
- Issues that pass functional tests but fail security tests
- Harder to detect without security expertise
Invicti vulnerabilities:
- Obvious configuration mistakes
- 1,182 apps out of 20,000 used the exact string “supersecretkey”
- Easy to detect with simple scanning
- Easier to fix once identified
5. Why They Don’t Actually Disagree
These studies are measuring different aspects of the same problem, one being more complex than the other in terms of vulnerabilities, but both equally important as they are both relevant to modern security operations:
- Invicti is right that modern LLMs have improved at avoiding basic coding vulnerabilities like SQL injection when writing simple queries
- SusVibes is right that LLMs still fail catastrophically at complex security logic in real-world scenarios
Invicti’s own example shows proper SQL parameterization and input validation in a simple endpoint, which aligns with their finding. But this doesn’t contradict SusVibes’ finding that when tasks become complex (repository-level, multi-file changes, subtle timing considerations), AI agents introduce serious vulnerabilities.
Final Analysis?
- For simple, standalone features: Invicti is correct—modern LLMs are getting better at basic security
- For complex, real-world applications: SusVibes is correct—AI still produces dangerously insecure code
The real concern is that hardcoded secrets are “built into models” from training data (Invicti study), while SusVibes shows that complex security logic requiring contextual understanding remains beyond current AI capabilities. Both are serious problems, but SusVibes’ findings are more concerning because those vulnerabilities are harder to detect and fix.
Kudos to the research done by the research Songwen Zhao, Danqing Wang, Kexun Zhang, Jiaxuan Luo, Zhuo Li, and Lei Li as well as Bogdan Calin on the Invicti research. Please see their work cited above in the source for deeper details and analysis.

