Automating CVE-2019-1436 Variant Analysis: An Intro to Detecting Information Leaks via IDAPython
An Introduction to Detecting Information Leaks via IDAPython

Date
Authors
Grant Willcox
Follow Us
In this previous blog post: Analyzing CVE-2019-1436 on Windows 10 v1903, VS-Labs, VerSprite’s Security Research practice, discussed an information leak within Windows 10 (which was originally thought to be a silently patched vulnerability until Matt Miller of MSRC pointed out that the bug was CVE-2019-1436).
After investigating the bug in more detail, VS-Labs Researchers decided to try seeing how feasible it would be for an attacker to create an IDAPython script that could discover CVE-2019-1436 and other similar memory leaks automatically.
During this post we will not only examine how this was done, but also review the benefits and limitations of IDAPython when it comes to finding memory leaks. In addition, we will review IDAPython code explanations that demonstrate the type of tasks IDAPython can help automate. (Check out VerSprite’s GitHub here).
An Introduction to IDAPython
IDAPython has been around for several years now, with the earliest known version dating back to 2005 based on old version tracking websites.
Whilst it was previously provided separately from IDA Pro itself, since IDA Pro 5.4 it now comes standard with every IDA Pro installation. But why is IDAPython so helpful?
To answer this, and to better understand the relevance of IDAPython, one needs to understand that before IDAPython, the only scripting support available in IDA Pro was IDC. IDC was clunky and utilized a C like language for its code, which slowed script development down significantly.
People who used IDC in the past have also reported it as being “clumsy and slow” and ill-suited to plugin development.
To solve these issues, IDA’s developers came up with IDAPython, which provided a way to interface with the underlying IDC scripting interface that people were familiar with, whilst also providing the power of the Python scripting language and the associated modules that Python supported.
By merging an integrated Python interpreter into IDA that could access the same APIs as IDC yet interact with the resulting objects in powerful ways, IDAPython was able to take over IDC as the dominant scripting language of choice among IDA Pro plugin developers. Nowadays almost all script developers use IDAPython; it is very rare to still see someone using the IDC scripting language.
IDAPython Base Modules
Over time IDAPython has grown and expanded into several modules, each of which contain a different set of functionalities. For starters, here are the base modules. These modules are the most common modules utilized in scripts, as they contain most of the foundational API to perform many common tasks:
- idc – The IDC compatibility module, which contains many of the base functions and functionality that exist in the IDC scripting language. Also includes internal bit definitions.
- idautils – A module containing the IDA Pro utility and convenience functions. Think of this as a very small toolbox of useful functions that combine the functionality of several API calls into one API call.
- idaapi – Many internal definitions are located within this module. Also includes a few function calls which can come in handy here and there, although these aren’t documented very well.
IDAPython Expansion Modules
Beyond these base modules, there are several other expansion modules that perform very specific tasks. They are included in *IDA Installation Path*python and are specialized in performing tasks related to one specific area of functionality. The following is a list of some of the more interesting modules:
- ida_bytes – Tons of useful functions for getting the values of bytes in memory, aligning data, changing data types, adding comments, and doing binary searches.
- ida_kernwin – Lots of modules for interacting with the GUI of IDA, such as setting hooks on certain actions, and displaying specific IDA views to the user.
- ida_hexrays – This module contains IDA APIs related to the HexRays Decompiler.
For more documentation on IDAPython’s various modules and their associated functions, constants, and purposes, refer to IDAPython’s support page.
Overview of Script Objectives
In order to create a script that detects a bug such as CVE-2019-1436, it is important to map out the various steps and stages that the script will go through in order to obtain the information required.
By breaking the larger issue down into a series of simpler tasks, it is easier to focus on properly developing each individual piece, rather than becoming overwhelmed by the project as a whole.
To this extent the following requirements will need to be met within the script:
- Check whether the current location of the user’s cursor resides within a function or not. If it is not within a function, there is no point in proceeding, as the rest of the code will fail.
- Given a function, retrieve the list of basic blocks associated with that function.
- Determine which of these basic blocks is the return block, or in other words, the block that contains a RET/RETN instruction that will redirect execution to its caller.
- Determine which blocks have a least one branch that leads directly to the return block and save them into an internal list. These blocks are the ones that will be targeted to see if they have an information leak. Doing things in this manner removes the need to keep a state tracker that tracks the state of various registers and memory throughout the function, something that is difficult to do with IDAPython alone.
- Check that none of the instructions between the instruction that sets RAX to the kernel address to be leaked, and the RET/RETN instruction located in the return block modify RAX in any way. If any instructions do, the leak should be considered invalid, unless RAX is overwritten with the address of another kernel pointer, in which case the output should be updated to reflect that a separate kernel leak is potentially occurring.
Obtaining the Basic Block List
To obtain the basic block list in IDAPython, one first needs to get the function object for the current function.
This can be obtained by calling the function idaapi.get_func(), which takes in one argument, a virtual address, and returns the function object corresponding to the function that address resides in, or None if it doesn’t belong to any function.
In the code, this is done by first calling here() to retrieve the virtual address that the user’s cursor is currently on, after which idaapi.get_func() is then called to get the function object for the function associated with this virtual address.
If None is returned by idaapi.get_func() the code exits as the address where the user’s cursor resides is not located within a function. Alternatively, a message is output to let the user know that the address where their cursor resides was identified as being part of a function.
def main(): # Print banner printBanner() # First let's get the function object for the current function. functionObject = idaapi.get_func(here()) try: if (functionObject == None): print("This is not a function! Exiting!") return -1 except: print("Looks like this is a function. Continuing...")Crafting the Flow Chart and Obtaining the Return Block
Once the function object has been successfully obtained, one can gather the basic blocks associated with that function.
In order to do this, one can ask for the function’s call graph, also known as a flow chart, by passing the function object returned from idaapi.get_func() to the function idaapi.FlowChart() which takes in a single argument: the function object to create the flow chart from, and returns an array of basic blocks representing the call tree of the function itself.
The script performs this task by passing the functionObject variable, which contains the result of the earlier idaapi.get_func() call, to idaapi.FlowChart().
The result of the idaapi.FlowChart() call is then saved into the local variable flowChart, after printNumFunctionBasicBlocks() is called to print out the number of basic blocks in the function by retrieving the size attribute of flowChart.
# Now let's get its flowchart. flowChart = idaapi.FlowChart(functionObject) try: if (flowChart == None): print("Could not build a flow chart! Exiting!") return -1 except: print("Exception occurred when trying to find the flowchart! Exiting!") return -1 # Print out info about the number of basic blocks # found in the current function. Comment this out # if you are not interested in seeing this in the output. printNumFunctionBasicBlocks(flowChart) .... def printNumFunctionBasicBlocks(flowChart): # And for reference let's obtain the function name using get_func_name() # Then print this out along with the number of basic blocks in the function. print("%s has %d basic blocks!" %(idaapi.get_func_name(here()), flowChart.size))Once the flow chart has been obtained the next step is to obtain the address of the return block. This responsibility is performed by the findReturnBlockOffset function, which takes in one argument, the flowChart array containing each of the basic blocks in the function.
For each of the basic blocks in the flowChart array, findReturnBlockOffset will check if that block’s type property, which will be a value from the enumeration fc_block_type_t, is set to 2, or fcb_ret. If it is, the block is a return block.
Once the return block has been found, findReturnBlockOffset will return the value of returnBlockOffset, or the entry within the flowChart array where the return block is located.
The address of the return block is then retrieved by grabbing the return block’s startEA property, which is then saved into returnBlockStartEA for later use.
# Locate which basic block within the flow chart array is the one that is the basic block containing the ret/retn instruction. returnBlockOffset = findReturnBlockOffset(flowChart) if (returnBlockOffset == -1): return -1 # Get the address in virtual memory where the basic block containing the ret/retn instruction is located. returnBlockStartEA = flowChart[returnBlockOffset].startEA ... def findReturnBlockOffset(flowChart): returnBlockOffset = 0 while (returnBlockOffset < flowChart.size): if flowChart[returnBlockOffset].type == idaapi.fcb_ret: # Taken from https://www.hex-rays.com/products/ida/support/sdkdoc/gdl_8hpp.html#afa6fb2b53981d849d63273abbb1624bd # which shows that block type 2 is fbc_ret, or a return block. break else: returnBlockOffset += 1 if (returnBlockOffset > flowChart.size): print("Something is seriously wrong! Couldn't find the basic block that returns execution to the caller!") return -1 else: print("Found return block at offset %d in the flowChart array!" % returnBlockOffset) return returnBlockOffsetBuilding a Flow Table with Relevant Info
Now that the return block has been identified, the next step is to find the blocks that have a branch that directly leads to the return block. Normally this would be achievable by calling the preds() method on a basic block, however this method has been broken since at least 2017, as calling it will always return a blank object, regardless of how many branches lead to a given basic block. As of IDA Pro 7.4, which was released in October 2019, this bug has yet to been fixed.
To get around this issue, the script tries to make things a bit easier by building a “table” of info about the basic blocks so that information can be stored in one place without having to call APIs to retrieve it multiple times. This is done by using the function buildFlowTable() which will go through each basic block within flowChart and retrieve its successors by calling that block’s succs() function. This will then be saved into the local variable succsessorArray.
For each basic block in successorArray, the block’s starting address is retrieved by grabbing its startEA property and appending it to the end of the nextEntryArray array.
Next, flowTable is appended with the basic block number currently being processed, starting from 0, the starting address of the basic block currently being processed, the end address of the basic block being processed, and nextEntryArray, which will be an array containing the starting addresses of all of the other blocks reachable via the current basic block’s branches.
After this, entryNumber is incremented so that the code will process the next entry in flowChart, and nextEntryArray is cleared so it can be filled in with the next basic’s blocks successors.
Finally, when everything is done, the populated flowTable is returned to main(), where it is saved in flowTable.
# Build the flow table from the flow chart that we currently possess. flowTable = buildFlowTable(flowChart) … # Build out the flow table in the variable flowTable, given a function flow chart. def buildFlowTable(flowChart): flowTable = [] entryNumber = 0 while (entryNumber < flowChart.size): nextEntryArray = [] successorArray = flowChart[entryNumber].succs() for i in successorArray: nextEntryArray.append(i.startEA) flowTable.append([entryNumber, flowChart[entryNumber].startEA, flowChart[entryNumber].endEA, nextEntryArray]) entryNumber += 1 return flowTableEDIT: After publishing this article, Ilfak Guilfanov, the creator of IDA Pro and IDAPython, tweeted VS-Labs to let us know that the preds() function works in IDA Pro, however its functionality is disabled by default unless the FC_PREDS flag is set when creating the flow table. This can be done in the script by replacing the following line:
flowChart = idaapi.FlowChart(functionObject)With this line:
flowChart = idaapi.FlowChart(functionObject, None, 0x4)This will tell IDAPython to create a flow chart with the predecessor functionality enabled by specifying the FC_PREDS flag, which has a value of 0x4. Since the following section’s code was mainly done as a hack to get around this perceived limitation, it is likely that the script could be improved by altering the idaapi.FlowChart() function call mentioned previously and then replacing lines with calls to the preds() function.
Enumerating the List of Basic Blocks That Lead to the Return Block
Once the flow table has been created, it can be utilized to create a list of blocks whose successors include the return block.
In the script, the function responsible for performing this work is enumerateBlocksThatJumpDirectlyToReturnBlock() which takes in two arguments: the flow table that was created, and the address where the return block starts in memory.
The enumerateBlocksThatJumpDirectlyToReturnBlock() function goes through each basic block in the flow table and finds that basic blocks successor blocks.
For each successor block that is found, the function will check if the successor blocks address is the same as returnBlockStartEA, the address of the return block. If it is, then the starting address, end address, and position within the flowTable array (aka entryNumber) of the basic block is saved into the array blocksThatHitReturnBlockDirectly.
When all basic blocks associated with the flow table have been processed, the blocksThatHitReturnBlockDirectly array is returned to main(), where it is saved in the local variable blocksThatHitReturnBlockDirectly.
# Enumerate basic blocks that jump directly to the block containing the ret/retn address, and save them into an array. blocksThatHitReturnBlockDirectly = enumerateBlocksThatJumpDirectlyToReturnBlock(flowTable, returnBlockStartEA) def enumerateBlocksThatJumpDirectlyToReturnBlock(flowTable, returnBlockStartEA): blocksThatHitReturnBlockDirectly = [] for entry in flowTable: for nextBlock in entry[3]: # entry[3] is nextEntryArray element of flowTable, which is an array of successor blocks. if nextBlock == returnBlockStartEA: blocksThatHitReturnBlockDirectly.append([entry[0], entry[1], entry[2]]) # Items are entryNumber, start address of the basic block, and end address of the basic block, in that order. return blocksThatHitReturnBlockDirectlyHow to Check That the Return Block Doesn’t Alter RAX/EAX
Finally, before checking if any data is leaked, the code checks to ensure that the return block doesn’t corrupt the value in RAX/EAX in any way.
This is necessary to check that RAX/EAX isn’t being set to some hardcoded value such as 1 or 0 in the return block, which is a common way to mitigate info leaks. In the script, the doesReturnBlockModifyRAX() function is responsible for performing this job.
It takes in the start and end address of the return block, and goes through each line of its code, checking to see whether it is a mov or xor instruction whose first operand is rax or eax.
If a line doesn’t match these criteria, idc.next_head() is called with currentEA, which stores the current instruction being examined, to get the address of the start of the next instruction to examine. doesReturnBlockModifyRAX() then returns False if no matches were found, or True if a match was found. This return value is then used to set the flagReturnAddressModifiesRAX flag in main().
# Verify that the return block doesn't have anything that modifies RAX, as the script currently doesn't support such functions. flagReturnAddressModifiesRAX = doesReturnBlockModifyRAX(returnBlockStartEA, flowChart[returnBlockOffset].endEA) … def doesReturnBlockModifyRAX(returnBlockStartEA, returnEndEA): currentEA = returnBlockStartEA while currentEA < returnEndEA: if (idc.print_insn_mnem(currentEA) == "mov"): if (idc.print_operand(currentEA, 0) == "rax") or (idc.print_operand(currentEA, 0) == "eax"): return True elif (idc.print_insn_mnem(currentEA) == "xor"): if (idc.print_operand(currentEA, 0) == "rax") or (idc.print_operand(currentEA, 0) == "eax"): return True currentEA = idc.next_head(currentEA) return FalseFinding Blocks That Taint RAX
Once flagReturnAddressModifiesRAX is set to the return value of doesReturnBlockModifyRAX(), the code in main() will check whether or not flagReturnAddressModifiesRAX is set to True.
If it is set to True, then it will print out an error message stating that the script does not support return blocks that modify RAX/EAX. Support for this feature was not added for two reasons.
The first was that adding this support would have made the script more complex, and detracted from learning the basics of IDAPython. Secondly, adding full support for this feature would require the script to have taint analysis support to track the movement of data between registers; something that can be achieved much more easily and accurately with dynamic analysis.
If you are interested in seeing how such a task could be achieved by using dynamic analysis we highly encouraged you to read j00ru’s BochsPwn Reloaded paper, which talks about this in much more detail.
If the code determines that flagReturnAddressModifiesRAX is set to False, it will call findPotentialDataLeaks() with the argument set to blocksThatHitReturnBlockDirectly.
This will ensure that all basic blocks who have at least one branch that goes to the return block will be checked for data leaks. Within findPotentialDataLeaks(), each block’s starting address and end address will be retrieved and saved into blockStartEA and blockEndEA respectively. Following this, the value of blockStartEA is saved into currentEA so that currentEA can serve as an instruction pointer to the address of the current instruction being processed.
idc.print_insn_mnem() is then called and is passed one argument: the address of the instruction to retrieve the mnemonic from. A mnemonic is the first part of an instruction, so in the case of mov rax, rsp, mov would be the mnemonic, rax would be the first operand, and rsp would be the second operand.
Once the code has determined that mnemomic is mov, it will then check if the first operand is rax by calling idc.print_operand(), which takes in the address of the instruction to inspect, and the number of the operand to grab, starting from 0 (first operand) and outputs the string representation of that operand.
If the first operand is determined to be rax, the program then conducts a final check using idc.get_operand_type().
idc.get_operand_type() takes in an address, and the number of the operand, starting from 0, and returns a o_XXX constant. The values of the o_XXX constants are documented on the group_o documentation page.
The check will ensure that the second operand is of type idaapi.o_mem, which IDA Pro defines as a “direct memory data reference whose target address is known at compilation time”.
This is needed to ensure that the second operand is leaking a data pointer and not something insignificant like a constant value which is not of use to an attacker. If this check is passed, then the script will print out a message to let the user know that there may be a potentially useful data leak.
Finally, since there is a chance RAX could be altered somehow between the point that it is set to a data pointer, and the time that the basic block jumps to the return block (which has already been confirmed to not alter RAX in any way), the code performs the same set of operations on the following instructions, and checks to see if any of them alter RAX.
If any of the following instructions alter RAX, and they do not set RAX to another data pointer (aka the second operand is not of type idaapi.o_mem), then the script will print out a message informing the user that the data leak detected was a false positive.
Otherwise it informs the user that there may instead be a different data leak, prints out the information about this data leak, and continues processing the code within the basic block. Note that idc.next_head() is also used here once again to get the address of the next instruction to examine, allowing for the code to easily iterate through each of the instructions in the basic block, up to blockEndEA.
if (flagReturnAddressModifiesRAX == False): findPotentialDataLeaks(blocksThatHitReturnBlockDirectly) else: print("Return block modifies EAX. This is currently not something that this function can rectify. Manual analysis recommended.") return -1 … def findPotentialDataLeaks(blocksThatHitReturnBlockDirectly): for block in blocksThatHitReturnBlockDirectly: blockStartEA = block[1] blockEndEA = block[2] currentEA = blockStartEA flagHitMovEAX = False # Uncomment the following line to see the start and end positions of each of the blocks in the array blocksThatHitReturnBlockDirectly #print("Block Start: %x Block End: %x" %(blockStartEA, blockEndEA)) while (currentEA < blockEndEA): if (idc.print_insn_mnem(currentEA) == "mov"): if (idc.print_operand(currentEA, 0) == "rax"): if (idc.get_operand_type(currentEA, 1) == idaapi.o_mem): # Thanks to https://www.hex-rays.com/products/ida/support/idapython_docs/idc-module.html#get_operand_type and more specifically # https://www.hex-rays.com/products/ida/support/sdkdoc/group__o__.html#gac180aea251826e5e5e484905e116c4cc for breaking this down and showing # that the value 2 is really o_mem aka Direct Memory Reference (DATA) or a direct memory data reference whose target address is # known at compilation time. if flagHitMovEAX != True: print("Potentially leaking %s at %x" %(idc.print_operand(currentEA, 1), currentEA) ) flagHitMovEAX = True currentEA = idc.next_head(currentEA) # Need this as we don't want to repeat the same result we just detected. while (currentEA < blockEndEA): if (idc.print_insn_mnem(currentEA) != "test"): # Quick filter here of blacklisted memnomics that essentially do nothing to RAX and that we can safely ignore. if (idc.print_operand(currentEA, 0) == "rax") or (idc.print_operand(currentEA, 0) == "eax"): if (idc.get_operand_type(currentEA, 1) != idaapi.o_mem): print(" [!] Looks like leak wasn't true. RAX/EAX gets clobbered at %x" %(currentEA)) else: print(" [*] Interesting, looks like we may have had RAX overwritten with another leak. Updating...") print("Potentially leaking %s at %x" %(idc.print_operand(currentEA, 1), currentEA) ) currentEA = idc.next_head(currentEA) currentEA = idc.next_head(currentEA)Script Demonstration
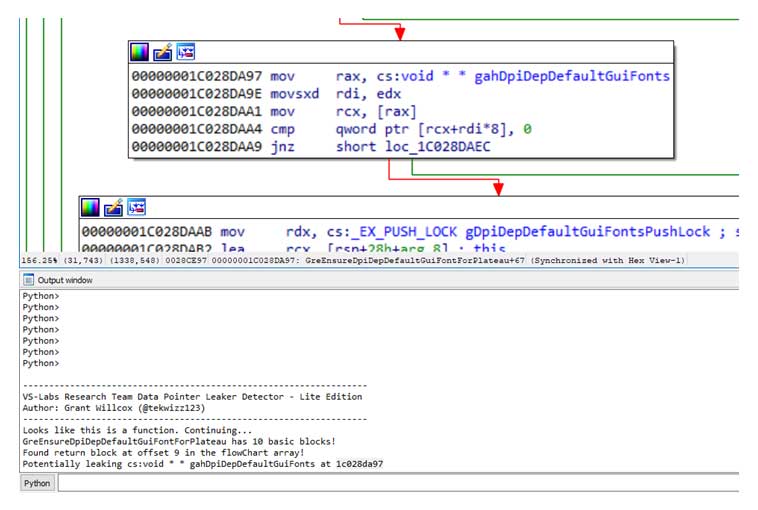
Running the script on the GreEnsureDpiDepDefaultGuiFontForPlateau() function reveals the potential data leak that used to exist, as well as the exact address of the instruction responsible for the data leak. This demonstrates that CVE-2019-1436 could be found using automated analysis with IDAPython or similar tools, all with minimal prior knowledge of OS internals.
------------------------------------------------------------------ VS-Labs Research Team Data Pointer Leaker Detector - Lite Edition Author: Grant Willcox (@tekwizz123) ------------------------------------------------------------------ Looks like this is a function. Continuing... GreEnsureDpiDepDefaultGuiFontForPlateau has 10 basic blocks! Found return block at offset 9 in the flowChart array! Potentially leaking cs:void * * gahDpiDepDefaultGuiFonts at 1c028da97Clicking on the address in the output window should result in IDA focusing on the exact line responsible for the data leak:
Figure 1 – Detecting CVE-2019-1436 within the codeConclusion and Limitations
It should now be apparent that, it is possible to detect some basic memory leaks such as CVE-2019-1436 automatically using a relatively short amount of IDAPython scripting, which can help analysts quickly and accurately identify where possible info leaks may be occurring within a program.
It is important to note however that this script does have several limitations. Presently, the script cannot analyze data as it passes through various functions, mainly due to its inability to keep track of the program’s state over time.
Additionally, the script only checks if data is leaked via the return address and does not account for other mechanisms by which data may be leaked, such as inside structures that are returned to user-mode. Such tasks are easier to perform with dynamic analysis techniques where system level memory analysis is possible.
For an example of how this might be done, we recommend readers look into j00ru’s BochsPwn Reloaded paper, which contains a wealth of information as to how system-level dynamic analysis can be performed against Windows.
VerSprite Security Research
Maintain awareness regarding unknown threats to your products, technologies, and enterprise networks. Organizations that are willing to take the next step in proactively securing their flagship product or environment can leverage our zero-day vulnerability research offering. Our subscription-based capability provides your organization with immediate access to zero-day vulnerabilities affecting products and software. Contact VerSprite →
View our security advisories detailing vulnerabilities found in major products for MacOs, Windows, Android, and iOS.
Share