Part 2: Comprehensive Research of Linux Operating System
Part 2. User and Kernel Modes. In Depth Look at Device Drivers

Date
Authors
Batuhan Irmak
Follow Us
This is a second part in the Linux OS Research series. Read the Previous article on Linus OS Research.
So far, we have discussed structure, components, and architecture of Linux operating system. We established that each running process has an authority and limits to what it can do. In this section, we explore how these boundaries and privileges are shaped and even how they can change. We analyze User Mode and Kernel Mode, what the modes were developed for, and how the two are related. Finally, we take a close look at the system’s drivers.
User Mode and Kernel Mode: Why?
Although it seems to be a part that provides the CPU processing power on the computer, it is actually the management center of this composition called Computer, which is formed by combining a set of equipment. It is the essential part for accessing and managing every connected device. But these accesses should always be under control. In fact, issues such as who can access, how and when, and which action will be performed in what order, should also be under control. Otherwise, the integrity will be broken. Today’s computers have the capacity to perform millions of operations in milliseconds. In fact, although each operation is done sequentially, these operations are reflected as if they were done at the same time, with the OS control. Every process has its own memory space and every process generates its own data, so they need to be protected. These processes may even need to send and receive network packets to communicate with the outside world. If each application accesses the CPU as it wishes, each application can interfere with memory areas that do not belong to it, read and change the data of other applications, and manage or even change communication packets belonging to other applications. In order to avoid such confusion, there are two authorization levels at the CPU, Kernel Mode and User Mode. Let us examine them in order.
-
Kernel Mode
In Kernel mode, the CPU has instructions to manage memory and how it can be accessed, plus the ability to access peripheral devices like disks and network cards. The CPU can also switch itself from one running program to another.
-
User Mode
In User Mode, access to memory is limited to only some memory locations, and access to peripheral devices is denied. A process running in User Mode cannot keep the CPU for its own work, the CPU can be taken from this process at any time.
Nearly all high-level applications are run in User Mode. Thus, each application remains free within its own limits, and no application can access the data of another. However, which software runs in kernel mode, and how does it manage all the switching between the programs and ensure that access to resources is correctly permitted/denied, as well as allocating resources equitably?
This is where the operating system comes into play. As we mentioned before, this huge chunk of C code has the ability to do everything on the computer without restrictions, when we come to the topic of the syscall we will better understand how this C code helps other applications.
User Mode and Kernel Mode: How?
In the CPU, there is a register or flag which records the mode the CPU is in: user or kernel mode. When the computer starts, the CPU is completely in kernel mode. It has unlimited access to all resources and starts to load and run the operating system after the boot phase. From this point on, when an application is started, the operating system loads the application’s instructions from the disk, then creates memory space for the application. Before jumping to the first instruction of the application, the CPU lowers its privilege level and the application continues its life in User Mode. In this way, the privileges of the application are restricted and a safer working area is provided for the application
-
Switching from User to Kernel Mode
We have examined and understood the differences between User Mode and Kernel Mode and the reasons for their existence so far. So, how does User Mode communicate with Kernel Mode? For example, a simple C code you write may ask you for an input. You transmit this input to the application via your keyboard, but as we said before, applications running in User Mode do not have the ability to access peripheral devices. Only Operating System can do this. In other words, if an application running in User Mode wants to perform an action that is not within its authorization, it requests the operating system to do it for itself. This is where the System Call mechanism comes into play. User Mode applications can run in Kernel Mode with this mechanism, but they have no control over the instructions which will be performed in Kernel mode, they can only act with higher privileges on the route given to them. The System Call mechanism has been implemented on CPUs as a trap instruction. We can call this mechanism a syscall or a trap instruction, they are the same thing. So how does this mechanism work? At bootup, kernel sets MSR_LSTAR register to point to the syscall handler routine, so the path to be followed during any syscall is determined, and thus the route we mentioned above has emerged. Before the application performs the syscall instruction, it puts values in registers or creates a stackframe containing the arguments to indicate what it wants to request from the Operating System. In the next step, syscall instrustion is run, Privilege Level switches to Ring 0 from this moment, Return address is assigned to RCX, and RIP is directed to syscall Handler by assigning value of MSR_LSTAR. Here, syscall Handler evaluates the desired service and arguments and performs this request in Kernel Mode. After the requests of the application running in User Mode are done, it is time to go home. At this point, a return instruction equivalent to syscall is used, for example, sysret. The sysret instruction, which will be triggered upon returning, has a structure that will completely reverse what syscall has done.
Switches Privilege Level to Ring 3. Jumps Control Flow to the value stored in the RCX register. And the return home is carried out successfully.
Here is a step by step list of what syscall and sysret instructions do.
-
High Level Overview of Switching from User to Kernel Mode (syscall):
-At bootup, Kernel sets MSR_LSTAR register to point to the syscall handler routine.
-When User Mode process wants to interact with Kernel, it calls syscall instruction.
-CPU Privilege Level switches to Ring 0.
–RIP register is set with the value of MSR_LSTAR register.
-Return address stored in RCX register. -
High Level Overview Of Switching from Kernel to Usermode (sysret):
-After completing the syscall task, Kernel calls sysret instruction.
– CPU Privilege Level switches to Ring 3.
-Control flow jump to RCX register.
-The process continues the normal flow.
User Mode – Kernel Mode Virtual Memory Address Spaces Relationship
As we have seen before, applications running in User Mode have their own addresses and these addresses are prohibited from being accessed by other User Mode applications. However, there is no such restriction for Kernel Mode. We now know that the CPU Privilege level of the application is changed to Ring 0 during the System Call. But another important detail that needs to be mentioned here is that System Calls do NOT switch the virtual memory map, but Kernel memory is only accessible from Ring 0. Actually, there is no change in the memory mapping of the application during System Call. Another detail that is worth mentioning is User Mode processes have their virtual memory at Low Addresses. However, Kernel has its virtual memory at High Addresses. There is actually a stack mechanic here. We can talk about downward growth as in the same stack, so it is logically the same.
Linux Device Drivers
As we mentioned in the beginning, this composition, which we call a computer, is formed by the combination of certain parts. As each part has tasks it undertakes, these parts also have certain needs in order to fulfill their duties. In this section we cover Drivers. We take a close look at the Drivers as a whole, as well as examine them from different angles. We explain what they are, what tasks they perform, their classes, and working logic.
-
Introduction to Device Drivers
First of all, we can say that the CPU is not the only intelligent device in the system. In fact, each part of the computer has certain special abilities in its own way. For example, each hardware component has its own control and status registers (CSRs), which differ between devices. These registers are used to start and stop the device, to initialize it, and to diagnose any problems with it. You can have multiple devices of different types on the computer. But without the drivers, these devices would not function. In other words, all processes, from controlling these different types of devices to managing them and making them workable for the user, are in a way the responsibility of the Device Drivers and they provide various interfaces to the operating system to manage these different types of devices. In fact, The Linux Kernel device drivers are, essentially, a shared library of privileged, memory resident, low-level hardware handling routines. However, the main tasks that they all focus on is to make different types of devices meaningful by abstraction the handling of devices for the end-user, and providing convenience for the user to use directly.
All hardware devices look like regular files, a communication network can be created using basic syscalls like open, read, write, and close. In this way, a meaningful exchange of information with devices can be achieved. Every device in the system associated with filesystem nodes named device special file that was created with the mknod command. They describe the device using major and minor device numbers.
Let us take a closer look at the concepts of device special file and major/minor device numbers that we have explained, they deserve special attention as they are important and difficult to understand. You can find the device special files of the devices you use in the Linux operating system in the /dev folder. The files you see here contain the class and the major minor number information about the devices they are connected to. The major and minor numbers we mentioned here are used to distinguish devices from each other and to ensure their connection with the appropriate driver. All devices controlled by the same device driver have a common major device number. The minor device numbers are used to distinguish between different devices and their controllers. For example, each partition on the primary disk has a different minor device number, but also, they have the same major device number. Because all these partitions connect to the same device. In addition, device numbers are also used as indexes for vectors such as chrdevs, blkdevs, blk_dev, which we will discuss later in the section. An additional issue that should be mentioned here is that not every device type can be mapped to filesystem nodes at a high level so easily. When we examine the device classes, we will discuss it in detail, but for now, we have the following to say. Not being a stream-oriented device, a network interface isn’t easily mapped to a node in the filesystem, as /dev/tty is. They have also represented by device special files but they are created by Linux as it finds and initializes the network controllers in the system.
Classes of Devices
Linux supports three types of hardware device: character, block, and network.
-
Char Devices
Just like in a regular file, we access the character devices with a stream of bytes. Drivers must implement system calls such as open read-write for character devices. Many devices in the /dev folder are character devices. The important thing to know about this device type is that they are like a data channel, but the flow is only one way. In other words, you cannot exchange data back and forth like with a normal file. There is a continuous and unidirectional flow. Of course, there are also character devices that do not fit this definition and that you can transfer data back and forth in a flow. For example, Frame Grabbers. Another point about character devices is that they can be defined as filesystem nodes. That is, they have device special files such as /dev/tty, /dev/console, /dev/cuse.
-
Block Devices
It is possible to access block devices, just like character devices, via filesystem nodes. In most Unix systems, block devices can only handle read or write operations that transfer one or more whole blocks, which are usually 512 bytes (or a larger power of two) bytes in length. But in Linux, the case is different. Applications can read or write data from block devices in any size they want, just like character devices. But block and character devices are completely different from each other in the kernel in terms of data processing and interfaces. Also, block devices are accessed via the buffer cache and maybe randomly accessed, in other words, any block can be read or written no matter where it is on the device. Although they have a device special file, the most common method to access block devices is filesystem. Additionally, only a block device can support a mounted file system.
-
Network Devices
Network devices are one of the most important parts of the computer that provide communication with the outside world. They take an active role in any data transfer with the outside world. A physical device was a necessary factor for the character and block devices. But this is not valid for network devices. Pure software network devices can be found, like the loopback interface, and for this reason, this section is considered as Network Interfaces in the classification for a more general meaning. A network interface is in charge of sending and receiving data packets, driven by the network subsystem of the kernel, without knowing how individual transactions map to the actual packets being transmitted. Although many network protocols such as TCP are stream-oriented, network devices do not have such a feature. Their task is just to receive and send the necessary packages. The driver for these devices has no information about matching sent or received packets to individual connections, it only handles packets. As we mentioned above, since they are not stream-oriented, they cannot be easily mapped to device special files in filesystem nodes. Because more than one interface is needed for the use of such devices. Here the Kernel plays an important role in processing sent and received packets. Processes such as who owns the sent and received packets are carried out by the kernel. Although special names are assigned to network devices in order to use them (such as eth0), there is no device special file in filesystem where these names match as with character and block devices. Finally, another detail that should be known is that network devices do not work with the help of syscalls such as character and block devices. Instead of read and write, the kernel calls functions related to packet transmission.
Common Attributes of Device Drivers
-
Kernel Code
Since Linux has a monolithic kernel, Device drivers are part of the kernel. Any errors or vulnerabilities related to drivers can completely affect the entire computer.
-
Kernel Interfaces
All device drivers have to provide certain interfaces for the tick to use. Thanks to such interfaces, the kernel can use the features of devices at high level and generate meaningful data from them.
-
Kernel Mechanism and Service
Just as the kernel uses device drivers, device drivers also take advantage of the opportunities that the kernel will offer them where necessary. For example, memory allocation, interrupt delivery, and wait queues to operate.
-
Loadable
One of the most important features that Linux offers to its users is, undoubtedly, the drivers and modules that can be loaded at runtime. Drivers and modules that can be loaded at any time can be easily disabled when not needed.
-
Configurable
Linux device drivers can be built into the kernel. And they can be configured during this installation, it is possible to change their structure on request and use it in that state.
-
Dynamic
As the system boots and each device driver is initialized it. Drivers start looking for the devices they are responsible for. Not finding the devices they are looking for does not prevent the computer from working, they only use some memory space without causing any damage.
-
-
Polling and Interrupts
When command is given to devices, device driver has two choices to find out that the given command has been completed or not. The device drivers can either poll the device or they can use interrupts. Let us examine these two methods in order.
-
Polling
Polling means constantly checking the CSR register to find out the status of the device. In this way, an inference is made about whether the given command is completed or not. But device drivers can also be assumed to be kernel codes, in which case the kernel will literally be stuck until the device does the task assigned to it. In order to prevent this, device drivers use system timers, so they create call routines in the kernel at certain intervals and check the status of the device. Thus, a more efficient process emerges. Although it tries to be efficient, Polling is a much more inefficient mechanism than Interrupts, which are generally used today.
-
Interrupts
In this scenario, if the device needs to communicate with the kernel, it will raise a hardware interrupt. The Linux kernel needs to be able to deliver the interrupt from the hardware device to the correct device driver. This is achieved by the device driver registering its usage of the interrupt with the kernel. It registers the address of an interrupt handling routine and the interrupt number that it wishes to own. In this way, it is understood by the driver that it is necessary to communicate with the device and the necessary routines are started to be applied. You can see which interrupts are being used by the device drivers, as well as how many of each type of interrupts there have been, by looking at /proc/interrupts. The Interrupt numbers you see here are of great value for pairing devices with drives. Interrupt numbers, also known as IRQs, may sometimes remain unchanged for some devices. Formerly, certain devices
can receive the same Interrupt number on every computer and every time. At boot time, device drivers must first discover the interrupt number (IRQ) of the device that it is controlling before it requests ownership of that interrupt. In addition, the CPU operates in a special mode so that no other Interrupts occur during any interrupt. In this way, Interrupt confusion is avoided. If a device driver has to do a lot of work during the Interrupt, this whole work can be broken up into chunks and a queue routine is created to avoid overloading the Kernel.
-
Direct Memory Access (DMA)
There are processes such as processing and understanding the data obtained when a command given to the device is completed. However, these processes can sometimes take a long time. Keeping the kernel busy as little as possible is one of the most important details in order to keep the synchronization intact. DMA was invented to eliminate such problems. A DMA controller allows devices to transfer data to or from the system’s memory without the intervention of the processor. There are 8 DMA channels, of which 7 can be allocated to devices. After the drivers of the devices set the DMA channels with the appropriate addresses, the device can exchange data whenever it wants, with the necessary syscalls. After the transfer is finished, an Interrupt is created, thus saving time. During the transfer, the CPU is free to do other things. Although it offers great convenience, device drivers should be very careful when using DMA channels. DMA can only be used with physical memory. It knows nothing of virtual memory. In addition, DMA cannot access a whole physical memory, it has to work in a restricted and lockable space. In order not to damage the space that DMA has, it can be cleaned from processes that affect physical memory, such as swap. As in the Interrupt section, DMA channels also have devices and drivers to match. Each channel used represents an instrument. As in Gene Interrupt, DMA channel numbers of certain devices are fixed and do not change, while the rest can take a channel that is empty in bootup and use it. Linux tracks the usage of the DMA channels using a vector of dma_chan data structures (one per DMA channel). The dma_chan data structure contains just two fields, a pointer to a string describing the owner of the DMA channel and a flag indicating if the DMA channel is allocated or not. It is this vector of dma_chan data structures that is printed when you cat /proc/dma.
-
Memory
Linux device drivers cannot use a fixed process or virtual memory. Since device drivers can get Interrupt at any time, their operation based on a single process or memory may cause data loss. For these reasons, device drivers manage and store information about the devices they are responsible for using data structures, just like the kernel does. These data structures can be statically allocated, part of the device driver’s code, but that would be counterproductive as it makes the kernel larger than it needs to be. Also, most device drivers allocate kernel non-paged memory to hold their data. Linux provides kernel memory allocation and deallocation routines and it is these that the device drivers use. Kernel memory is allocated in chunks that are powers of 2. For example, 128 or 512 bytes, even if the device driver asks for less. The number of bytes that the device driver requests is rounded up to the next block size boundary. This makes
kernel memory deallocation easier as the smaller free blocks can be recombined into bigger blocks. There is another important detail we should mention. If a device manager wants to use DMA, he can indicate to the Kernel that the space to be allocated is suitable for DMA. In other words, device drivers cannot use DMA directly according to their wishes, the Kernel gives the final decision, and the kernel can allow it as long as it sees fit, according to the drivers’ request.
-
Interfacing Device Drivers with the Kernel
In Linux systems, each device must have an interface to be used by the kernel. It is important for the kernel to use devices rather than their types or differences. For this reason, each device driver creates data structures that the kernel can easily use. These structs contain information about the device and the routines of the functions that can be used, so that at high level, the kernel can communicate with the device and make it do whatever it wants, thanks to these interfaces. Now let’s take a look at how device drivers create these data structures and what they contain.
-
-
-
Character Devices
Character devices behave like files in the same filesystem. In their simplest form, they are based on system calls such as open read write. At bootup, character device driver registers itself with the Linux kernel by adding an entry into the chrdevs vector of device_struct data structures. The device’s major device identifier (for example, 4 for the tty device) is used as an index into this vector. Each entry in the chrdevs vector, a device_struct data structure contains two elements; a pointer to the name of the registered device driver and a pointer to a block of file operations. The file operations specified here contain the addresses of the file operations that the device driver has, such as read write open. In other words, we can think the addresses of the file operations as addresses of functions that can be used. The information about the character devices in the /proc/devices file in Linux is created with using the chrdevs vector. Here you can see the device’s major number and the name of the driver it is managed.
-
Block Devices
The mechanisms used for block devices and character devices are almost the same at high level. Block devices also support being accessed like files. The blkdevs vector is used for block devices, the same routines apply here as with chrdevs. The device major number is used as the index and the blkdevs vector is a device_struct data structure. Every block device driver must provide an interface to the buffer cache as well as the normal file operations interface. Each block device driver fills in its entry in the blk_dev vector of blk_dev_struct data structures. The index into this vector is, again, the device’s major number. The blk_dev_struct data structure consists of the address of a request routine and a pointer to a list of request data structures, each one representing a request from the buffer cache for the driver to read or write a block of data. Since block devices are segmented devices, a different routine comes into play at this point. But the working logic of the blk_dev vector is the same as the other two vectors we discussed.
-
Network Devices
As we mentioned before, network devices are only responsible for sending and receiving packets. All remaining processes are executed by the kernel, and network device drivers have to provide the necessary interfaces to the kernel for the execution of these processes. Some networks may have physical hardware, while others are only software devices (such as loopback interface). Each network device is represented by a device data structure. Network device drivers register the devices that they control with Linux during network initialization at kernel boot time. The device data structure contains information about the device and the addresses of the functions that allow the various supported network protocols to use the device’s services. All sent and received network packets are defined by the sk_buff data structure. Due to its flexible data structure, it allows easy deletion or modification of network protocol headers. The device data structure contains certain information about the device, let us examine this information briefly.
-
Name
Unlike character and block devices, the mknod command is not used to create a device special file in the filesystem for network devices. At bootup, if these devices are identified by the network device drivers, these files are automatically created, but the uses are not like character and block devices. So, as we mentioned previously, although they have a device special file, these files are much different for network devices. They are named according to the sequence number, and this continues in a sequential order. For example, eht0, eth1, eth2.
-
Bus Information
Here is the necessary information for the device driver to manage the device. Such as IRQ number, DMA channel number, control status registers base address of the device.
-
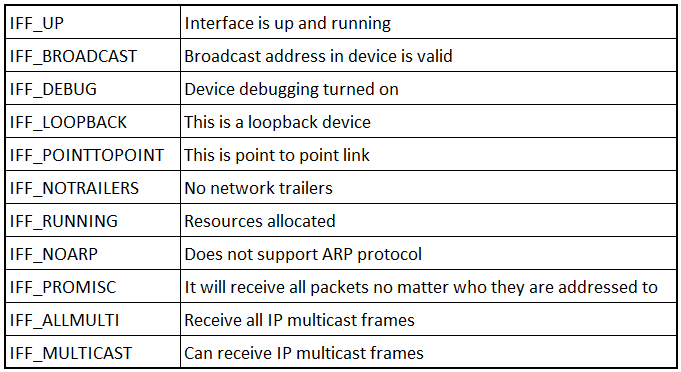
Interface Flags
The part that specifies the characteristics and capabilities of the device.

-
Protocol Information
Contains information on how the device will use the protocols. It also contains information such as resource capacity and family type.
-
mtu
Specifies the maximum packet size that the network can provide. According to the protocol used, the maximum amount of data that can be sent and received is determined by mtu.
-
Family
Specifies the protocol family the device supports. The protocol family of all network devices in Linux operating systems is AF_INET.
-
Type
The variable that defines the hardware interface type. In other words, it contains information about which interface the device is connected to the computer (ethernet, wifi, etc.)
-
Address
It is the section that holds a number of addresses relevant to this network device, including the inet (IPv4), inet6 (IPV6), mac address of the device.
-
Packet Queue
Specifies the sk_buff data structures waiting in the queue. A little reminder: All sent and received network packets are actually sk_buff data structures.
-
Support Functions
As we discussed at the beginning, there are certain routines (functions) provided by the device driver. Using them, it is possible to manage the device and obtain information about the device. For example, the ifconfig command uses these support functions to show us information about devices.
-
Initializing Network Devices
Network devices are represented by the device data structure within the network device list pointed at by dev_base list pointer. These data structures contain initialization routines. At boot, the device is recognized and operational with these startup routines. During initialization, if the required device is not found, its entry in the device list pointed at by dev_base is removed. This data structure continues to be filled with the devices found, so at the end of the day, only the existing devices are taken into consideration. Another thing that needs to be mentioned; devices are dynamically allocated to the ethN device structure during initialization. In this way, sequential numbering (eth0, eth1, eth2) is successfully completed.
-
-